Unveiling the Pioneers: A Study of Leading Vector Database Technologies
Introduction:
In today’s digital age, we’re surrounded by an overwhelming amount of data. From the songs we stream to the photos we share, the digital footprints we leave are vast and varied. But have you ever paused to wonder how platforms like Spotify or Pinterest seem to “know” our preferences so well? How do they manage to recommend songs that resonate with our current mood or suggest images that align perfectly with our aesthetic?
The answer, often unbeknownst to many, lies in the intricate world of vector databases. These aren’t your typical databases that store data in rows and columns. Instead, they operate in a realm where data is transformed into multi-dimensional vectors, capturing the very essence of the content. It’s a world where data isn’t just stored; it’s understood.
But what does this all mean? Why is there a shift from traditional databases to vector databases? And how do these vector databases manage to bridge the gap between raw data and human-like understanding? As we delve deeper into this guide, we’ll embark on a journey to unravel the magic behind vector databases, exploring their intricacies, applications, and the transformative impact they have on our digital experiences. So, fasten your seatbelts, dear reader, as we navigate the fascinating landscape of vectors and the databases that harness their power.
The Basics: Traditional Databases vs. Vector Databases
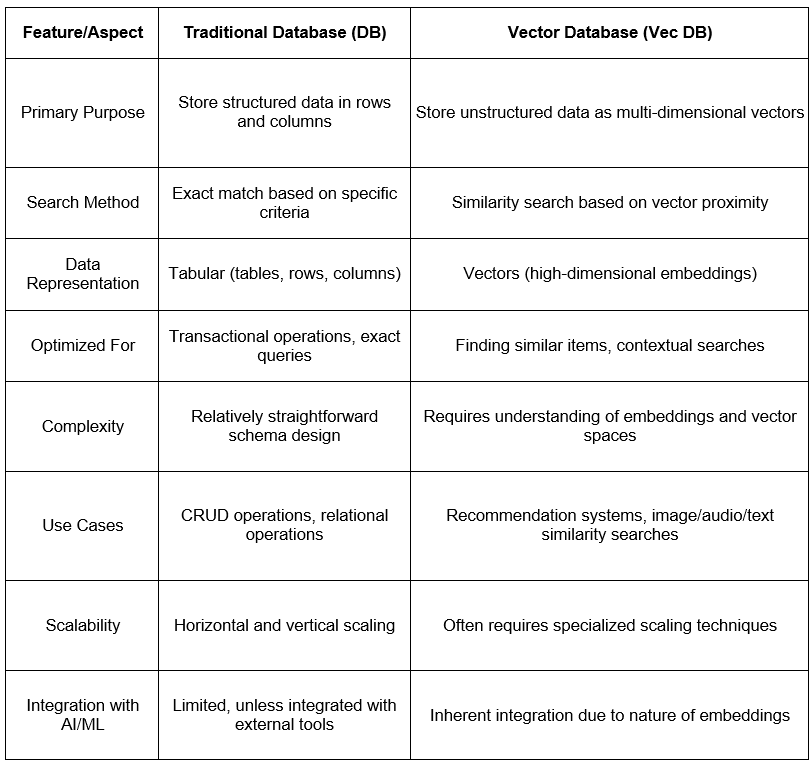
Traditional Databases (DB)
Traditional databases, often referred to as relational databases, have been the backbone of data storage for decades. They are designed to store structured data, where each piece of data has a predefined schema. This means that before storing data, we need to define tables, columns, and relationships.
Strengths:
Structured: Data is organized, making it easier to manage and query.
ACID Properties: Ensures data reliability with properties like Atomicity, Consistency, Isolation, and Durability.
Mature Ecosystem: Established tools, best practices, and a vast community.
Limitations:
Not Ideal for Unstructured Data: Handling data like images, audio, or free-form text can be challenging.
Exact Match Limitation: Primarily relies on exact matches, which might not capture nuances or context.
Vector Databases (Vec DB)
Vector databases are a newer entrant, designed to handle the complexities of unstructured data. Instead of storing data in tables, they convert data into vectors using embeddings. These vectors capture the essence of the data, allowing for similarity-based searches.
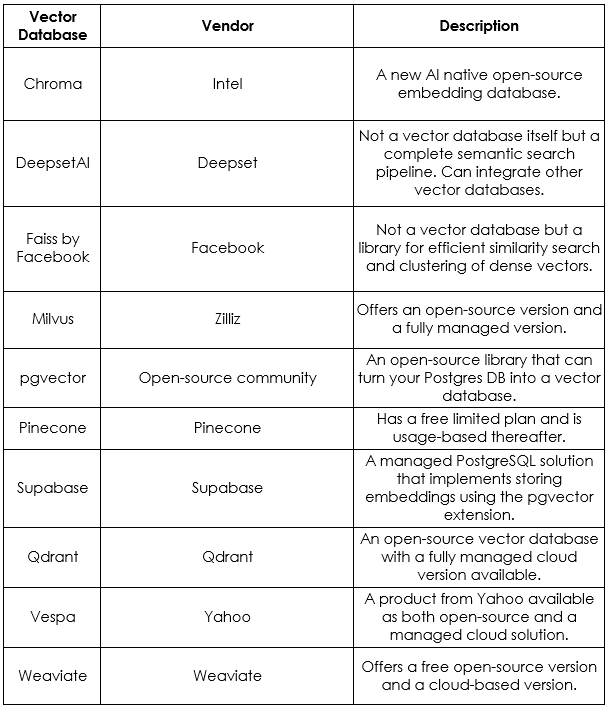
Vendor list for Vector DB
Strengths:
Handles Unstructured Data: Can efficiently store and search through images, audio, text, etc.
Contextual Searches: Doesn’t rely on exact matches; understands context and nuances.
AI/ML Integration: Seamlessly integrates with machine learning models, enhancing capabilities.
Limitations:
Complexity: Requires a deeper understanding of embeddings, vector spaces, and similarity metrics.
Still Evolving: While powerful, the ecosystem is still maturing with evolving best practices.
As we move forward in the digital age, the choice between traditional and vector databases will depend on the specific needs of applications. While traditional databases will continue to play a crucial role in many sectors, vector databases are paving the way for more intuitive, context-aware digital experiences.
Vectors & Embeddings: The Heart of the Matter
In the vast universe of data science and artificial intelligence, two terms often stand out due to their significance: vectors and embeddings. They form the foundational pillars upon which many modern AI applications are built. But what are they, and why are they so crucial? Let’s dive deep into these concepts.
Vectors: The Language of Machines
At its core, a vector is a mathematical object that has both magnitude and direction. But in the context of data, think of vectors as lists of numbers that represent information.
Analogy: Imagine describing a fruit to someone. You might use attributes like color, size, taste, and texture. In the world of data, these attributes can be represented as numbers, and when you put them together in a list, you get a vector!
Why Vectors?
Uniformity: Whether it’s an image, a piece of text, or a sound clip, everything can be represented as a vector, providing a consistent way for machines to process varied data.
Computational Efficiency: Algorithms can process vectors faster, enabling real-time operations and analyses.
Embeddings: Crafting the Vectors
While vectors are powerful, the question arises: how do we convert our data into these number lists? This is where embeddings come into play.
Definition: Embeddings are algorithms or methods that transform data (like words, images, or sounds) into vectors. The magic lies in how these embeddings capture the essence and context of the original data.
Examples:
Word Embeddings: Convert words or sentences into vectors. Words with similar meanings will have vectors close to each other. For instance, “king” and “queen” might be closer in vector space than “king” and “apple”.
Image Embeddings: Transform images into vectors, capturing features like shapes, colors, and patterns. Two pictures of cats, even if they’re different breeds, will have similar vectors.
Significance of Embeddings:
Dimensionality Reduction: Embeddings can compress vast amounts of information into smaller, manageable vectors.
Context Preservation: They ensure that the relationships and nuances in the original data are maintained in the vector form.
Interoperability: Once data is in vector form, it can be compared, analyzed, and processed using a common set of tools, irrespective of its original form.
vectors and embeddings are the unsung heroes behind many of the AI-driven features we use daily. From the song recommendations on Spotify to the image searches on Google, these concepts work tirelessly behind the scenes, ensuring that machines understand and cater to our needs in the most intuitive way possible.
The Art of Similarity: How Vector Databases Shine
In a world overflowing with data, finding the right piece of information can often feel like searching for a needle in a haystack. Traditional databases excel at fetching exact matches, but what if we’re looking for something “similar” or “related”? This is where vector databases come into their own, offering a unique approach to data retrieval.
Understanding Similarity
Before diving into how vector databases operate, it’s essential to grasp the concept of “similarity.” In the realm of vectors, similarity isn’t about exact matches. Instead, it’s about how close two vectors are in a multi-dimensional space.
Analogy: Think of a vast space filled with stars. Each star represents a piece of data. Now, if two stars (data points) are close to each other, they share similarities. The closer they are, the more similar they are.
Nearest Neighbors: The Core of Vector Searches
The primary mechanism behind vector databases is the search for the “nearest neighbors.” When you query a vector database, it doesn’t look for an exact match. Instead, it searches for vectors that are closest to the query vector.
How It Works:
Query Transformation: First, the query (be it text, image, or sound) is converted into a vector using embeddings.
Distance Measurement: The database then calculates the “distance” between the query vector and all other vectors in its storage.
Ranking & Retrieval: Vectors with the shortest distances (most similar) are ranked and returned as results.
Metrics of Similarity
How do we measure the “distance” or “similarity” between vectors? Several metrics come into play:
Cosine Similarity: Measures the cosine of the angle between two vectors. If the vectors are identical, the cosine is 1, and if they’re entirely different, it’s 0.
Euclidean Distance: Think of it as the straight-line distance between two points in space. The closer the points, the shorter the distance.
Hamming Distance: Used primarily for binary data, it counts the number of positions at which the corresponding bits are different.
Why Similarity Matters
In our evolving digital landscape, the need for contextual and related information is paramount. Whether it’s a content recommendation system suggesting articles based on reading habits or an e-commerce platform recommending products based on browsing history, capturing the essence of similarity enhances user experience.
In essence, vector databases redefine how we perceive data retrieval. Moving beyond the confines of exact matches, they embrace the nuances and intricacies of data, ensuring that every search, every query, is met with results that resonate with the user’s intent and context.
Real-world Applications: Beyond the Hype
The concept of vector databases, with its high-dimensional vectors and similarity searches, might seem abstract and esoteric. However, its applications are deeply embedded in our daily digital experiences. Let’s explore some real-world scenarios where vector databases are making a tangible difference.
Music and Video Streaming Platforms
Example: Spotify, Netflix
How It Works: When you listen to a song on Spotify or watch a movie on Netflix, these platforms convert your preferences into vectors. As you engage more, your “user vector” evolves. When looking for recommendations, the platform searches for songs or movies with vectors close to yours, ensuring personalized suggestions.
E-commerce and Online Retail
Example: Amazon, ASOS
How It Works: Ever browsed for a pair of shoes and then got suggestions for similar styles? That’s vector databases in action. Products are converted into vectors based on attributes like color, style, and brand. When you search or browse, the platform offers products with vectors that align closely with your browsing history.
Image Recognition and Search
Example: Google Photos, Pinterest
How It Works: Upload a picture of a sunset to Google Photos, and it can instantly find other sunset images in your collection. These platforms transform images into vectors, capturing features like color patterns, shapes, and objects. Searching for similar images becomes a matter of finding close vectors.
Natural Language Processing and Chatbots
Example: Customer support chatbots, Virtual assistants
How It Works: When you interact with a chatbot, your queries are transformed into vectors. The bot then searches its database for responses or actions with the closest vector match, ensuring contextually relevant interactions.
Medical Imaging and Diagnostics
Example: Radiology image databases, AI-driven diagnostic tools
How It Works: Medical images, like X-rays or MRIs, are converted into vectors. When a new image is taken, it can be compared against a database of labeled images to identify anomalies, patterns, or conditions, aiding in faster and more accurate diagnoses.
Gaming and Virtual Reality
Examples: Game recommendation systems, VR content platforms
How It Works: Gamers’ preferences and interactions are transformed into vectors. Platforms can then recommend games or VR experiences that align closely with a user’s taste, enhancing engagement and user satisfaction.
while the underlying mechanics of vector databases might be complex, their impact is profoundly tangible. They’re reshaping how we interact with digital platforms, making our experiences more personalized, relevant, and intuitive. Far from being just a buzzword, vector databases are pivotal in driving the next wave of digital innovation.
The Intricacies: How Do Vector Databases Work?
Vector databases, with their promise of capturing the essence of data and delivering context-rich results, are undeniably fascinating. But beneath their seemingly magical operations lie intricate mechanisms and processes. Let’s peel back the layers and delve into the inner workings of vector databases.
Data Transformation: From Raw to Vector
The journey begins with raw data — a piece of text, an image, a sound clip. This data undergoes a transformation process called “embedding,” where it’s converted into a vector. Sophisticated algorithms, often powered by machine learning models, ensure that this vector captures the data’s core attributes and nuances.
Indexing: Organizing the Vector Space
Once data is in vector form, it needs to be organized or indexed for efficient searching. Indexing in vector databases isn’t about creating tables or lists. Instead, it’s about organizing vectors in a multi-dimensional space to ensure quick retrieval.
Methods:
Hashing: Algorithms like Locality-Sensitive Hashing (LSH) map similar vectors to nearby locations.
Quantization: Vectors are segmented into smaller chunks, represented with codes, and then reassembled during searches.
Graph-based Methods: Vectors are visualized as nodes in a graph, with similar vectors connected by edges.
Query Processing: The Search for Similarity
When a user queries a vector database, the query itself is first transformed into a vector. The database then calculates the “distance” between this query vector and the indexed vectors.
Distance Metrics:
Cosine Similarity: Measures the cosine of the angle between two vectors.
Euclidean Distance: Calculates the straight-line distance between vectors.
Hamming Distance: Especially useful for binary data, it counts differing bits between vectors.
The vectors with the shortest distances (indicating high similarity) are then retrieved and ranked as results.
Post-processing: Refining the Results
After the initial retrieval, results might undergo further refinement. This can involve:
Filtering: Removing results based on specific criteria.
Ranking: Adjusting the order of results based on additional factors like popularity or relevance.
Aggregation: Grouping similar results for a more organized presentation.
Scalability and Performance Optimization
As data volumes grow, vector databases employ various strategies to ensure performance doesn’t degrade:
Sharding: Splitting the database into smaller, manageable chunks.
Replication: Creating copies of data to ensure high availability and fault tolerance.
Caching: Storing frequently accessed vectors in memory for faster retrieval.
Security and Access Control
Just like traditional databases, vector databases implement measures to safeguard data:
Encryption: Encrypting data both at rest and in transit.
Authentication: Ensuring only authorized users can access the database.
Auditing: Tracking and logging all database activities for review and compliance.
In essence, while vector databases might seem to operate on magic, they are a symphony of intricate processes and algorithms working in harmony. Their ability to understand and retrieve data based on context and similarity is a testament to the advancements in data science and artificial intelligence.
The Road Ahead: Future of Vector Databases
The digital landscape is ever-evolving, with data at its core driving transformative changes. As we generate and interact with increasingly complex data, the tools and systems that manage this data must also evolve. Vector databases, with their unique approach to data storage and retrieval, are at the forefront of this evolution. But what does the future hold for them? Let’s embark on a speculative journey into the horizon of vector databases.
Hybrid Systems: Best of Both Worlds
While vector databases excel at handling unstructured data and similarity searches, there’s still a vast realm of structured data that traditional databases manage efficiently. The future might see the rise of hybrid databases that seamlessly integrate the strengths of both traditional and vector databases, offering a unified solution for diverse data needs.
Enhanced AI Integration
The symbiotic relationship between vector databases and AI will only deepen. As AI models become more sophisticated, they’ll produce richer embeddings, making vector databases even more powerful. Conversely, vector databases will provide AI models with better-organized data, enhancing their training and performance.
Real-time Processing and Edge Computing
With the proliferation of IoT devices and the need for real-time data processing, vector databases might evolve to operate efficiently at the edge, closer to data sources. This would enable instant data embeddings and similarity searches, paving the way for real-time recommendations, alerts, and insights.
Semantic Understanding and Contextual Awareness
Future vector databases might not just rely on numerical vectors. They could evolve to understand the semantics behind data, leading to even more contextually relevant results. Imagine searching for “a nostalgic song from the 90s,” and the database understands the emotion and context, returning songs that resonate with that specific feeling.
Advanced Visualization Tools
As we deal with high-dimensional vector spaces, there will be a growing need for tools that can visualize this data effectively. Advanced visualization platforms will emerge, allowing users to explore, analyze, and interact with data in intuitive and meaningful ways.
Decentralized and Distributed Architectures
With the rise of decentralized technologies like blockchain, we might see vector databases adopting decentralized architectures. This would enhance data security, transparency, and resilience, ensuring data integrity and availability even in adverse conditions.
Ethical and Responsible Data Management
As vector databases become more ingrained in our digital experiences, there will be heightened discussions around data ethics, privacy, and responsibility. Future systems will need to prioritize user consent, data anonymization, and transparency, ensuring that the power of vectors is harnessed responsibly.
the road ahead for vector databases is filled with promise and potential. They are not just a passing trend but represent a paradigm shift in how we perceive, store, and interact with data. As they continue to evolve, vector databases will play a pivotal role in shaping a future where digital experiences are more personalized, intuitive, and meaningful.
Conclusion
The digital tapestry of our world is intricately woven with data. As we continue to generate, interact with, and rely on this data, the systems that manage it become increasingly critical. Vector databases have emerged as a beacon in this landscape, offering a fresh perspective on data storage and retrieval. They transcend the limitations of traditional databases, embracing the complexities of unstructured data and the nuances of similarity.
Through our exploration, we’ve seen how vector databases operate, their real-world applications, and the potential they hold for the future. Their ability to understand context, capture the essence, and deliver personalized results is transformative. It’s not just about storing data; it’s about understanding it, feeling its pulse, and making it accessible in the most relevant ways.
As we stand at this juncture, looking ahead, it’s evident that vector databases are more than just a technological innovation. They represent a shift in our digital ethos — a move towards more intuitive, human-centric experiences. In a world where data is often seen as cold and impersonal, vector databases bring warmth, understanding, and relevance.
In closing, the journey of understanding vector databases is a testament to our relentless pursuit of better ways to interact with the digital realm. They are not the end but a significant milestone in our ongoing quest to make technology more aligned with human intuition and needs. The future is not just digital; it’s vectorized.